
1. OpenAI APIの「利用上限」とは?
OpenAI API上限とは、利用者が自由に使える範囲を制御するために設定された制限のことです。これらはシステムの安定性や公平性を保つために設けられており、フリーランスエンジニアが案件で利用する際には必ず理解しておく必要があります。
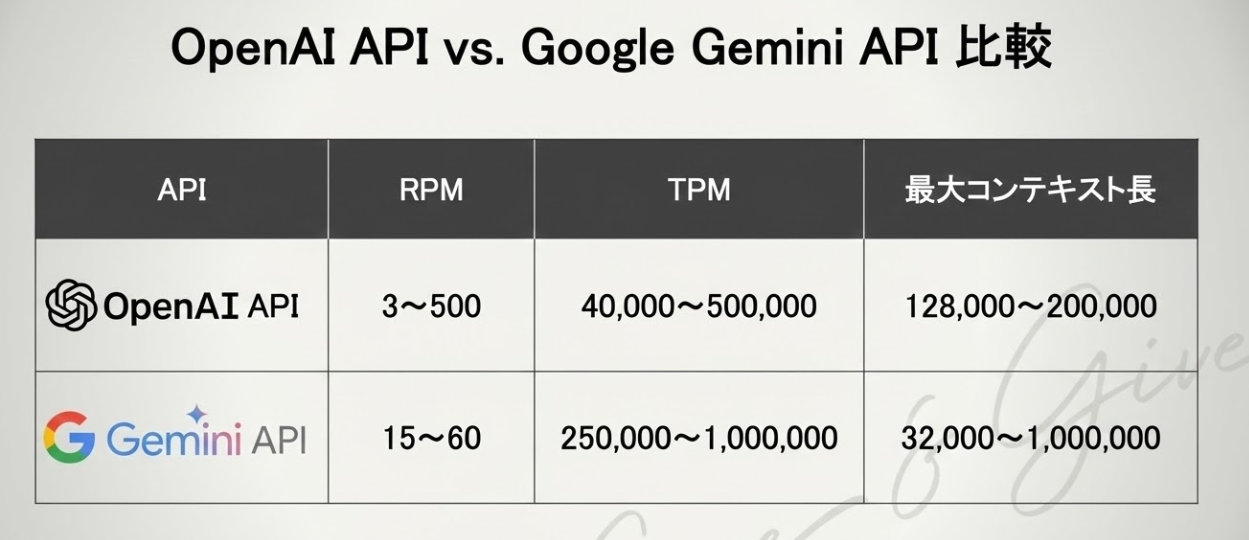
例えば、標準アカウントでは毎分3〜60リクエスト(RPM)、40,000〜1,000,000トークン(TPM)の制限が課されています。さらに最新のGPT-5では、最大コンテキスト長は200kトークン(入力+出力合算、2025年8月時点)に拡張されており、大規模アプリケーションの開発においても柔軟に対応できるようになっています(出典:OpenAI Docs, 2025年8月)。
OpenAI APIの基本的な活用方法については「ChatGPT API 活用方法」も参考にしてください。
1.1 OpenAI API上限の基本:リクエスト数の上限(Rate Limit)
APIには「一定時間あたりに送信できるリクエスト数」の制限があります。標準アカウントの場合、1分あたり3〜60RPMに制限されており、これを超えるとエラーが返されます。 一方でGoogle Gemini APIでは、最大で60RPM/900,000TPMが提供されており(出典:Google AI for Developers「速率限制」, 2025年8月)、競合比較をすることでOpenAIの優位性や限界を把握できます。大量ユーザーを想定するサービスでは、APIゲートウェイやキャッシュ戦略を併用して効率化を図ることが必須です。
1.2 OpenAI API上限の基本:トークン数の上限(入力+出力)
トークンとは、文章を分割した最小単位のことです。1リクエストあたりに扱えるトークン数には上限があり、GPT-5の最大コンテキスト長は200kトークン(入力・出力合算)になりました。これにより長大な文書処理や複雑な解析が可能となる一方、コスト増大のリスクも伴います。
1.3 モデルごとの制約(GPT-5, GPT-4o, GPT-4, GPT-3.5)
各モデルには異なる制約があり、処理できるトークン数や速度、料金が変わります。案件の要件に応じて適切なモデルを選ぶことが重要です。
1.4 料金プランごとの利用枠
無料プランと有料プランでは利用できる上限が異なります。有料プランではより多くのリクエストやトークンを扱えますが、コストとのバランスを考える必要があります。
2. 2025年8月時点の最新情報
OpenAIは定期的に利用条件を更新しています。特に2025年8月7日にGPT-5が正式リリースされ、従来モデルよりも大幅に制限値が拡張されました。また、新たに reasoning_effort パラメータが導入され、複雑な推論タスクに応じて計算リソースを柔軟に調整できるようになっています(出典:OpenAI Blog, 2025年8月)。
2.1 無料枠と有料プランの違い
無料枠では試用的な利用に限られ、商用利用や大規模なリクエストには不向きです。有料プランでは上限が拡大されますが、料金体系は変動するため最新情報を確認する必要があります。
| プラン | 利用上限(RPM / TPM) | 商用利用 | 主な特徴 |
|---|---|---|---|
| 無料(Free) | 数リクエスト/分、数万トークン規模 | NG(試用のみ) | 基本的な試用、学習用に限定 |
| Pro(月額$20〜) | 数十RPM/数十万TPM | OK | ChatGPT Plus含む、GPT-4o/mini利用可 |
| Team | 数百RPM/数百万TPM | OK | チーム管理機能、SLA一部保証 |
| Enterprise | カスタム(要相談) | OK | 高いSLA保証、セキュリティ対応、専用サポート |
2.2 商用利用における制限
商用利用では、OpenAI 利用規約(Terms of Use, 2025年8月時点)に基づき制約が設けられています。特にエンドユーザー向けサービスに組み込む場合は、利用条件を満たしているかを事前に確認することが重要です。
2.3 高負荷時のスロットリング(リクエスト制御)
アクセスが集中すると、リクエストが一時的に制御されることがあります。これによりレスポンスが遅延する可能性があるため、サービス設計時に考慮しておく必要があります。
3. OpenAI API上限でフリーランスが直面しやすい問題
OpenAI API上限は、サービスのユーザー数が増えたり、長文データを扱ったり、複数モデルを併用したりすると、一気に現実的な制約として立ちはだかります。
典型的なパターンとしては、
- 想定以上の同時アクセスで**リクエスト数の上限(RPM)**に達する
- 長文の入出力でトークン上限を超えてレスポンスが途中で切れる
- モデルごとに異なるコンテキスト長やTPMがボトルネックになる
といった「足かせ」が発生します。
これらの問題をどのように回避・緩和するかは、次章「4. OpenAI API上限を回避・最適化する方法」で解説します。
3.1 ユーザー数増加時のAPI上限によるリクエスト制限
同時アクセスが増えると、APIのリクエスト制限に達してしまうことがあります。これにより一部のユーザーが利用できなくなるリスクがあります。
3.2 長文処理でのトークン上限超過
文章要約や長文生成では、トークン数が上限を超えてしまうことがあります。結果が途中で切れるため、分割処理や要約を組み合わせる工夫が必要です。
3.3 複数モデルを併用する際の制約
案件によっては複数のモデルを使い分けることがありますが、それぞれの上限が異なるため、設計段階で考慮しておく必要があります。
4. OpenAI API上限を回避・最適化する方法
上限設定はコスト管理とも密接に関わっています。実際に、あるスタートアップのチャットアプリではトークン制限を実装していなかったため、単一リクエストで50万トークンを消費し、1回の呼び出しで25ドルの請求が発生しました(出典:OpenAI Docs, 2025年8月)。
これらの工夫により、実際のコストを大幅に削減できます。
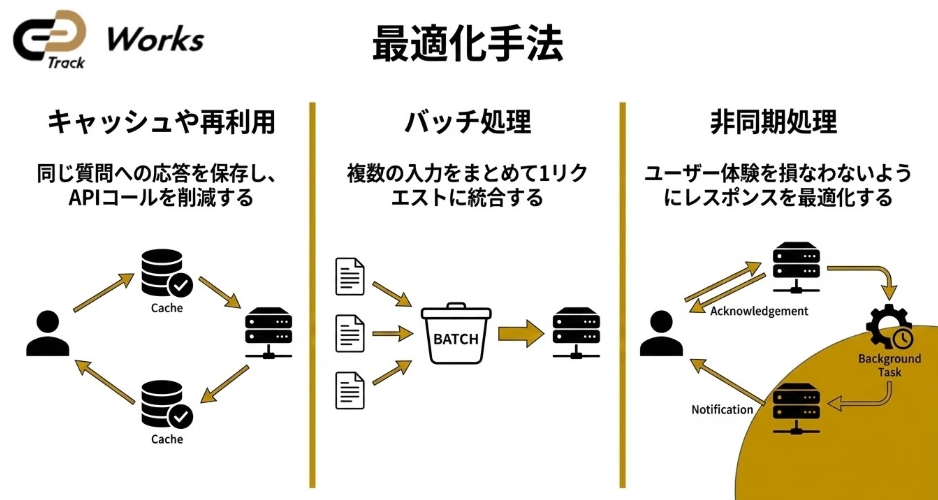
4.1 キャッシュ活用でAPIを上限内に収める方法
同じ質問や同じ出力結果を何度もAPIに投げるのは非効率です。 キャッシュ(保存した結果の再利用) を導入することで、APIコール数を最大30〜40%削減でき、結果的に月額数百ドル規模のコスト削減につながります。 実践ポイント
- RedisやMemcachedなどのインメモリキャッシュを利用
- 出力が頻繁に変わらない処理(翻訳、定型要約など)で特に有効
4.2 トークン上限対策のためのプロンプト最適化
プロンプト(入力文)が冗長だと、処理トークン数が増えてコストが跳ね上がるだけでなく、1リクエストあたりのトークン上限に近づき、エラーや回答が途中で途切れるリスクも高まります。
例えば、説明文を300トークン削減できれば、月間10万リクエスト規模の案件で数百ドル〜数千ドルの節約につながります。

4.3 バッチ処理・非同期処理でAPI上限を効率的に使う
1ユーザーごとに逐次APIを呼び出すと、リクエスト数が膨大になります。 複数の入力を**バッチ処理(まとめて送信)**したり、非同期処理を導入すると、レスポンス効率が大幅に改善されます。 効果
- 同期処理と比べてレスポンス遅延を20〜30%改善
- サーバーリソースの最適化で安定稼働 実践ポイント
- 複数ユーザーからの入力を1リクエストにまとめる
- Node.jsやPython asyncioを利用して並列処理を実装
4.4 モデル選択の工夫で上限とコストを最適化
モデルごとにコンテキスト長やRPM・TPMなどのAPI上限が異なるため、どのモデルをどこで使うかの設計は「上限対策」と「コスト最適化」の両方に直結します。
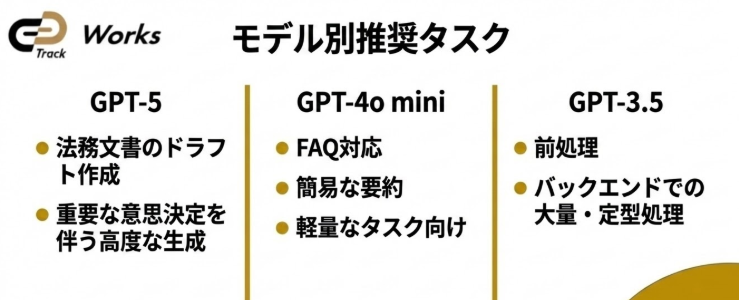
高性能モデル(GPT-5やGPT-4o)は精度が高い反面、料金も高額です。 一方で軽量モデル(GPT-4o miniやGPT-3.5)を併用すれば、処理コストを最大1/10まで圧縮できます。 使い分けの例
- 高精度が求められる部分 → GPT-5(200k対応)
- FAQや定型応答 → GPT-4o mini
- バックエンドでの要約・前処理 → GPT-3.5 実践ポイント
- モデル選択を案件ごとに明確に設計する
- プロンプトに「出力形式」を指定し、軽量モデルでも精度を担保
4.5 API上限の監視とアラート設定
最適化の実行だけでなく、監視とアラート設定 も必須です。 利用状況をリアルタイムで可視化し、閾値を超えたら通知する仕組みを導入することで、予算超過やサービス停止を防げます。 実践ポイント
- OpenAI APIのUsageダッシュボードで 月次・日次利用を確認
- DatadogやPrometheusで アラートを設定 閾値設定例: リクエスト数80%到達時に通知 → 余裕を持って対策可能
5. OpenAI API上限とコスト管理の関係
APIの利用上限はコストと直結します。フリーランスとして案件を受ける際には、見積もりや契約に反映させることが重要です。
5.1 APIの上限を考慮した利用料の見積もり方法
想定されるリクエスト数やトークン数をもとに、自分のプランのRPM / TPM上限をどの程度使うかを試算しながら、月額コストを見積もっておくと安心です。
トラフィックがピークに近づいたときの「最悪ケース」も含めてシナリオを用意しておくと、予算超過やスロットリング発生時の説明がしやすくなります。
5.2 上限超過によるコストリスク
上限を超えると追加料金が発生する場合があります。予算を超過しないよう、利用状況を常にモニタリングすることが大切です。
API上限超過によるコスト増大は、フリーランスにとって大きなリスクの一つです。その他のフリーランス特有のリスクと対策については「フリーランスエンジニアのリスク全解説」も参考にしてください。
5.3 クライアントへの説明ポイント
クライアントに対しては、上限やコストリスクを事前に説明し、合意を得ておくことが信頼につながります。
6. OpenAI APIを踏まえた案件での実務的注意点
フリーランスが案件でAPIを利用する際には、契約や合意形成の段階から注意が必要です。
6.1 契約前に確認すべきAPI上限と利用条件
- OpenAI利用規約の商用利用条項を必ず確認する(例:エンドユーザー向けサービスに組み込む際の条件)。
- 禁止事項(不適切な用途、法規制違反など)に抵触していないかチェック。
- 利用プラン(Free / Pro / Team / Enterprise)が案件規模に合っているかを確認し、 各プランごとのRPM / TPMなどのAPI上限を把握しておく。 誤って無料枠を前提に契約すると、リクエスト数超過で赤字リスクが発生します。
OpenAI利用規約の商用利用条項を必ず確認する必要があります。 フリーランスの契約書作成については「フリーランス 業務委託 契約書」も併せてご確認ください。
6.2 SLA(サービス品質保証)とAPI上限の関係
- エンタープライズ契約では SLA(稼働率99.9%保証など) が提示される場合あり。
- APIの上限(RPM / TPM)がボトルネックになると、SLA違反に見える障害が発生する可能性がある。
- 責任範囲の明確化:OpenAI側の制限か、フリーランス側の設計不備かを切り分けるための文言を契約に含めると安心。 クライアントが「SLA=常に高速応答」と誤解しないよう説明することが重要。
6.3 クライアントとの合意形成のポイント
フリーランスがOpenAI APIを案件で利用する際には、クライアントとの事前合意 が非常に重要です。 事前に説明すべき内容:
- 「API利用上限により一時的に応答が遅延する可能性がある」と説明する
- 追加料金リスク(例:想定以上のリクエストが来た場合)を契約に明記する
- 利用レポートを定期的に共有 し、透明性を確保する こうした合意をしておくことで、納品後に「こんなに遅いとは思わなかった」「予算オーバーした」といった クレームや炎上リスクを防止 できます。
7. OpenAI APIの上限に対応するための代替手段
OpenAI APIだけに依存せず、代替手段を検討することも重要です。
7.1 他社API(Anthropic, Google, Metaなど)の活用
他社の生成AI APIを組み合わせることで、上限の影響を分散できます。
| プロバイダー | モデル | 最大コンテキスト長 | 特徴 |
|---|---|---|---|
| Anthropic | Claude 3.5 Sonnet | 200k トークン | 長文要約に強い、安全性重視 |
| Gemini 1.5 Pro | 1M トークン | マルチモーダル対応、圧倒的な長文処理 | |
| Meta | Llama 3 (70B) | 約65k トークン | オープンソース、ローカル運用可 |
| OpenAI | GPT-5 | 200k トークン | reasoning_effort対応、幅広い業務に最適 |
「出典:Anthropic公式Docs / Google AI for Developers / Meta Llama3 Release / OpenAI Docs」
7.2 オープンソースLLMでAPI上限から解放される
オープンソースの大規模言語モデル(LLM)をローカル環境で運用することで、API上限に依存しない仕組みを構築できます。
7.3 APIゲートウェイで上限を制御する
APIゲートウェイを活用することで、リクエストの制御や分散を行い、上限に対応しやすくなります。
8. フリーランスとしての提案力を高める
単にAPIを利用するだけでなく、上限を理解し、それを前提に最適な設計を提案できることがフリーランスの強みです。これにより、クライアントから「任せても安心」と思われる存在になれます。
8.1 API上限を含む技術的リスクを事前に説明する
- API上限(RPM / TPM)により発生し得る 遅延・エラー・追加課金リスク を契約前に説明。
- 実際の数値例(例:GPT-5で200kトークン超過時にどう処理されるか)を提示すると説得力が増す。
- 提案書に「リスク軽減策(キャッシュ、バッチ処理)」を明記することで安心感を与えられる。
8.2 コストと性能のバランスを提案する
高性能モデルは必要な場面に限定し、軽量モデルを併用することでコストを最大70〜90%削減できる。 以下は、あるユースケースの例を紹介したスライドです。
8.3 継続的な改善を見据えた設計
- 納品後も 利用ログを分析し、改善案を定期的に共有 → 長期契約につながる。 提案例:
- 月次レポートで「今月のAPI利用量とコスト推移」を可視化
- トークン使用量の最適化による翌月コスト削減案を提示
- 単発案件ではなく 伴走型のパートナー として信頼を築ける
9. まとめ:OpenAI APIの上限を理解して2025年の案件に備えよう
OpenAI API上限は「RPM(リクエスト数)」と「TPM(トークン数)」の2軸で構成されています。2025年8月にリリースされたGPT-5では最大200kトークンまで対応し、reasoning_effortパラメータも追加されました。
OpenAI API上限を正しく理解し、他社API(Claude / Gemini / Llama3)との比較を通じて強みと限界を把握することが重要です。設計段階からキャッシュやコスト管理を行い、上限を前提とした提案ができるフリーランスエンジニアは、案件獲得において大きなアドバンテージを持てるでしょう。
生成AI分野でフリーランスとしてキャリアを築きたい方は「フリーランスエンジニア×生成AIキャリアガイド」もぜひご覧ください。





