
1. なぜ今、フリーランスエンジニアに「AI FinOps(コスト最適化)」が必要なのか?
AIアプリケーション開発が普及する2026年現在、開発のボトルネックは「推論能力」から「APIコストの制御」へと移行しています。特に固定報酬で案件を受けるフリーランスにとって、APIコストの増大は自身の利益を直接圧迫する可能性があり、重要な課題となります。
開発効率だけを追い求め、クラウドの財務管理(FinOps)を疎かにすることは、事業継続における最大の不確実性を抱え込むことと同義です。ここでは、AI時代のエンジニアにとって重要な財務リテラシーの重要性を解説します。
1.1 LLM案件で頻発する「クラウド破産」と利益圧迫のリスク
LLM(大規模言語モデル)のAPIコストは、ユーザーの利用量や履歴の蓄積によって徐々に増大する特性があります。無計画なループ処理や冗長なコンテキスト送信を放置すれば、一晩で数十万円の請求が発生する「クラウド破産」も珍しくありません。
特に請負契約(固定単価)の場合、想定外のAPIコストはそのままエンジニアの赤字に直結します。開発フェーズから本番運用まで、常にコストの「可視化」と「制御」を意識した設計が不可欠になるかもしれません。
1.2 クライアントが求める「APIコストへの説明責任」
企業側もAI導入のフェーズが進むにつれ、その投資対効果(ROI)に対して非常にシビアな目を向ける傾向にあります。単に「動くものを作る」だけでなく、「いくらのコストで運用できるか」という具体的な予測が求められています。
エンジニアは、推論コストの試算や削減策を論理的に提示する「説明責任」を負わなければならない可能性があります。コスト面での懸念を解消できるエンジニアは、クライアントからの信頼も厚く、長期的なパートナーとして選ばれやすくなります。
1.3 FinOpsスキルがフリーランスの単価と市場価値を上げる理由
「AI FinOps(AIに特化した財務運用手法)」を扱えるエンジニアは、2026年の市場において極めて希少な存在になりつつあります。単なる実装力だけでなく、企業のランニングコストを数分の一に削減する提案ができれば、それは「コンサルティング」の価値を持ちます。
結果として、時給単価の向上や高付加価値な案件への参画につながり、エンジニアとしての市場価値をより高めることができるかもしれません。コスト最適化は、クライアントの利益を守ると同時に、自分自身の市場価値を守るための「攻めのスキル」なのです。
2. 2026年最新版:主要LLM APIの価格体系と見落としがちな「隠れコスト」
AI FinOpsを実践する第一歩は、ベンダーごとに複雑化する課金モデルを正確に把握することです。2026年の市場では、単純な従量課金を超え、コンテキスト長や推論の深さに応じた多次元的なプライシングが主流となっています。
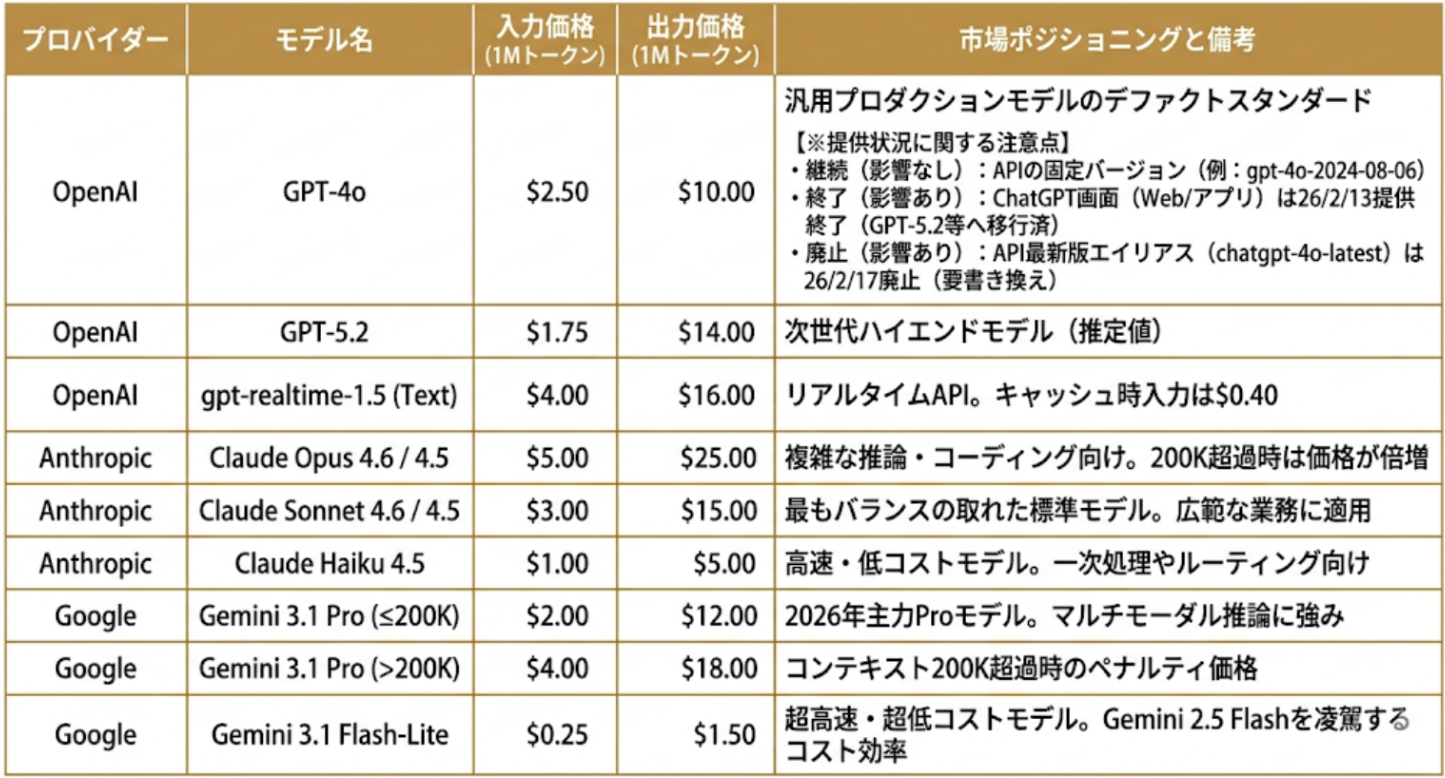
2.1 主要プロバイダーの3層構造モデルと最新価格トレンド
現在の主要プロバイダー(OpenAI、Anthropic、Google)は、モデルを「インテリジェンス層」「バランス層」「低コスト層」の3層で展開しています。例えばGoogleの「Gemini 3.1 Flash-Lite」は、入力100万トークンあたり0.25ドルという驚異的な低価格を実現しています。
一方で、最上位モデルである「Claude Opus 4.6」などは高い推論能力の代償として高額な設定となっています。タスクの難易度に応じて、安価なモデルへ積極的に処理を振り分ける「適材適所」の判断がコスト管理の鍵を握ります。
https://ai.google.dev/gemini-api/docs/pricing?hl=ja
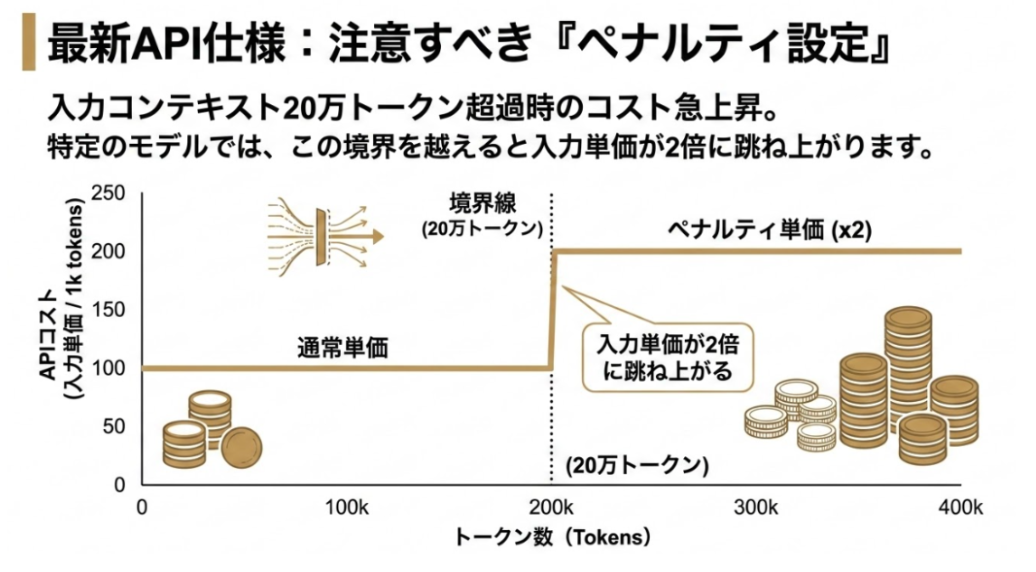
2.2 「200Kトークンの壁」と推論(Thinking)トークンの罠
最新のAPI仕様で注意すべきは、入力コンテキストが20万トークンを超えた際に単価が急上昇する「ペナルティ設定」です。特定のモデルでは、この境界を越えると入力単価が2倍に跳ね上がる設計が導入されており、長文の扱いに注意が必要です。
また、モデルが回答を出す前に「思考」するプロセス(Extended Thinking)も、高価な「出力トークン」として課金されます。見た目の回答が短くても、内部の思考プロセスで大量のトークンを消費し、予想外の請求が来るリスクを理解しておきましょう。
2.3 コンテナ課金とチャット履歴による「雪だるま式コスト」の仕組み
最新のエージェント機能(Code Interpreter等)を利用する場合、トークン代とは別に「コンテナセッション課金」が発生します。実行環境(OSのような仮想空間)を維持する時間単位でコストが積み上がるため、不要なセッションの解放が重要です。
さらに、チャットボットでは会話が長くなるほど、過去の履歴を毎回「入力」として送信し続ける必要があります。この「コンテキスト税」を放置すると、1回の返信コストが数円から数百円へと急増し、システム全体の経済性を破壊してしまいます。
3. コスト削減の第一歩:ネイティブ・キャッシングとバッチ処理の活用
API単価の低下を待つのではなく、アーキテクチャの工夫で「能動的」にコストを下げる手法が有効です。プロバイダーが提供する機能を正しく設定するだけで、数割から9割近いコスト削減が可能になるケースもあります。
3.1 プロンプトキャッシングの仕組みとプロバイダー別の課金特性
「プロンプトキャッシング」は、同一のシステムプロンプトや参照ドキュメントの再処理をスキップする技術です。サーバー側で過去の処理結果を保持(キャッシュ)し、2回目以降の入力コストを劇的に引き下げます。
AnthropicのAPIなどでは、キャッシュの「生成」には割増料金がかかる一方、その後の「読み取り」には90%の割引が適用されます。固定のガイドラインや巨大なソースコードを頻繁に参照するアプリケーションにおいて、この機能は必須の最適化と言えます。
3.2 損益分岐点を見極めたキャッシュの戦略的利用法
キャッシュ機能は「短時間に複数回アクセスする」場合に最大の効果を発揮します。有効期限(TTL)は一般的に5分から10分程度と短いため、アクセスの頻度(トラフィック)に応じた損益分岐点の見極めが必要です。
開発中のデバッグ作業などは同じコードを何度も読み込ませるため、キャッシュが非常に有効に働きます。一方で、アクセスが極めて稀な機能にキャッシュを設定すると、書き込み時のコストが相対的に大きくなり、結果としてコスト効率が低下する可能性にも注意が必要です。
3.3 コストを半減させる「バッチ処理API」の実装とユースケース
即時性が求められない処理(ログの要約、大量データの分類、翻訳など)には、「バッチ処理API」が最適です。リクエストをキューに溜め込み、最大24時間以内に処理される代わりに、料金が50%オフになるサービスが一般的です。
この機能は、長大なドキュメントの解析など「高コストだが急ぎではない」タスクと非常に相性が良いです。深夜帯にまとめて処理を実行するようなアーキテクチャへリファクタリングすることで、ランニングコストを大幅に抑制できます。
4. 推論をバイパスする:セマンティックキャッシュとVectorDBの導入
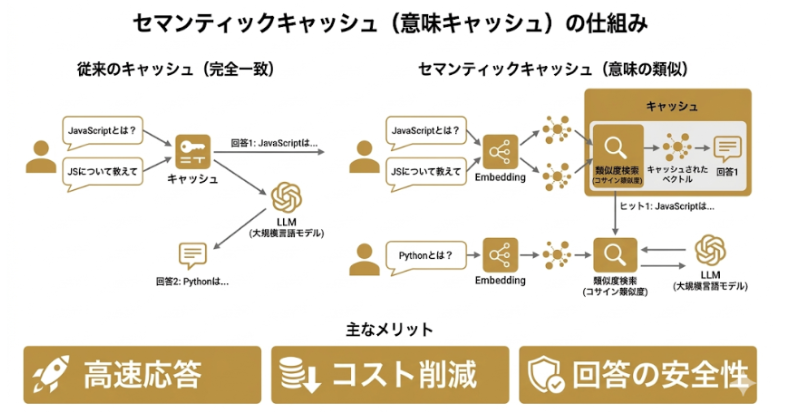
文字列の完全一致が必要なネイティブキャッシュに対し、言葉の「意味」の近さで判断するのが「セマンティックキャッシュ」です。これにより、LLMへの推論リクエストそのものをバイパス(スキップ)し、さらに深いコスト削減が可能になります。
4.1 セマンティックキャッシュの動作原理とメリット
セマンティックキャッシュは、ユーザーの質問をベクトル(数値の羅列)に変換し、過去の類似した質問に対する回答を返却します。例えば「パスワードを忘れた」と「ログインできない」という、表現は違うが意図が同じクエリを同一視できます。
LLMの推論には数秒かかりますが、キャッシュからの返却ならミリ秒単位で完了します。コスト削減だけでなく、ユーザー体験を劇的に向上させる点も、この手法の大きなメリットです。
4.2 VectorDBを用いた類似度検索の実装と閾値のチューニング
実装にはRedisやMilvusといった「VectorDB(ベクトルデータベース)」を使用します。質問の意味の近さを表す「閾値(しきいち)」の設定が極めて重要であり、通常は0.90〜0.95前後の類似度でキャッシュを返すように調整します。
閾値が低すぎると「似ているが答えが違う質問」に対しても誤ったキャッシュを返してしまいます。開発者は、実際のログを分析しながらこの精度を微調整し、システムの「正確性」と「経済性」のバランスを取る高度な技術が求められます。
4.3 開発中のAPI課金を抑えるオープンソースライブラリの活用
「GPTCache」などのオープンソースライブラリを活用すれば、こうした高度な機能を比較的容易に導入できます。既存のコードを数行変更するだけで、OpenAIやLangChainの呼び出しをセマンティックキャッシュ経由に差し替えることが可能です。
特にフリーランスが個人で開発・テストを行う際、この機能をローカル環境で動かすことで、無駄なAPI課金をほぼゼロに抑えられます。開発経費を削減しつつ、本番環境でも通用する「コスト効率の良いコード」を書く習慣を身につけましょう。
5. 複数モデルを使い分ける:LLMゲートウェイとダイナミックルーティング
すべての処理を最上位モデルで実行するのは、コストの観点では過剰となる場合があり、一般的には推奨されにくい設計とされています。クエリの内容や予算状況に応じて最適なモデルへ自動で振り分ける「ゲートウェイ」の概念を導入しましょう。
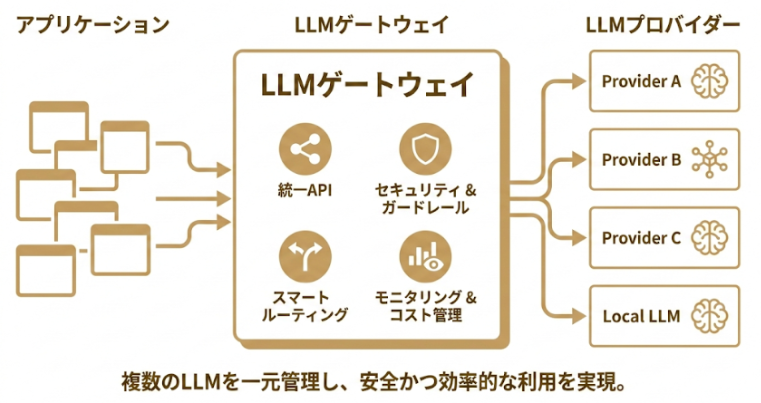
5.1 LLMゲートウェイによるトラフィック制御とAPIの統合
「LLMゲートウェイ」は、アプリケーションと各プロバイダーの間に位置するミドルウェア(仲介役)です。代表的なツールとして「LiteLLM」などがあり、複数のAPIを単一の形式で統合的に扱うことができます。
ゲートウェイを導入することで、特定のプロバイダーがダウンした際の「フォールバック(代替切り替え)」が容易になります。また、一箇所でトークン使用量を監視できるため、コスト管理の司令塔として機能します。
5.2 タスク難易度と予算に応じたダイナミックルーティング戦略
「ダイナミックルーティング」とは、クエリを分析してモデルを動的に選別する手法です。例えば、単純な挨拶や短い要約は安価な「Flash」モデルに、高度な論理推論が必要な箇所だけ「Opus」や「GPT-4o」に振り分けます。
このように「モデルのカスケード(段階的利用)」を行うことで、品質を維持したままコストを50%以上削減できる事例もあります。タスクの難易度を自動判定する「ルーター」を構築することも、2026年のエンジニアには推奨されるスキルです。
5.3 予算超過の原因を特定する「可観測性(Observability)」の確保
コスト最適化には「どこで誰が使っているか」をリアルタイムで把握する「可観測性」が欠かせません。特定のユーザーが不自然に大量のリクエストを投げていないか、特定のプロンプトが異常に多くのトークンを消費していないかを監視します。
詳細な実行トレース(記録)をキャプチャし、ダッシュボードで可視化することで、予算超過の兆候を早期に発見できます。クライアントへのレポート作成も容易になり、データの裏付けを持った改善提案が可能になります。
6. コンテキスト税を回避する:プロンプト圧縮技術のアプローチ
情報の精度を高めるためにコンテキスト(文脈)を増やすと、コストとレイテンシ(遅延)が比例して増大します。この物理的な制約を打破するのが、言語の冗長性を削ぎ落とす「プロンプト圧縮」という最新技術です。
6.1 情報理論に基づく「プロンプト圧縮技術」のメカニズム
自然言語には多くの「余計な情報」が含まれています。プロンプト圧縮は、情報理論に基づき、LLMが理解するのに必要な「最小限の重要トークン」だけを抽出するアプローチです(例:LLMLinguaなど)。
人間が読むと文法が崩れた不自然な文章に見えますが、LLMは欠落した情報を補完して正しく推論できます。これにより、意味を損なうことなく入力トークン数を大幅に減らすことが可能になります。
6.2 小規模モデルを用いたパープレキシティ(予測困難度)計算と間引き
圧縮のプロセスでは、手元で動く安価な「小規模モデル」を使用して、各単語の「パープレキシティ(予測困難度)」を計算します。予測しやすい(=情報価値が低い)単語を大胆に間引くことで、データの「濃度」を高めます。
この前処理を挟むことで、巨大なモデルへ送るデータを半分以下に削減できるケースもあります。ローカル環境で前処理を行い、本番のクラウドAPIには凝縮された情報だけを投げるという「ハイブリッドな最適化」が非常に効果的です。
6.3 圧縮による性能維持と、長文処理時のコスト削減効果
研究データによれば、プロンプトを数分の一から数十分の一に圧縮しても、LLMの回答精度(数学的推論など)はほとんど低下しないことが証明されています。長編小説や数百枚のドキュメントを読み込ませるRAGシステムでは、この圧縮技術が絶大な威力を発揮します。
特に「20万トークンの壁」を越えそうな長文を扱う際、圧縮によってペナルティ単価を回避できるメリットは極めて大きいです。コンテキストを「ただ増やす」フェーズから、「効率的に凝縮する」フェーズへと設計をアップデートしましょう。
参考文献 https://www.prompthub.us/blog/compressing-prompts-with-llmlingua-reduce-costs-retain-performance
7. 破滅的リスクを防ぐ:セキュアなAPIキー管理とセキュリティアーキテクチャ
どれほどコストを数円単位で削減しても、APIキーが盗まれて数万ドル規模の請求が発生すれば、エンジニアとしてのキャリアに深刻な影響が及ぶ可能性があります。セキュリティは、AI FinOpsにおける最も重要な「防御壁」です。
7.1 フロントエンドへのキー埋め込みなど「脆弱な設計」の排除
ブラウザ(JavaScript)やスマホアプリのコード内にAPIキーを直接書き込むことは、鍵をドアに挿したまま外出するようなものです。悪意のあるユーザーは、開発者ツールを開くだけであなたのAPIキーを奪うことができます。
「難読化したから大丈夫」という考え方は、2026年のセキュリティ環境では十分とは言えない場合があります。キーは、外部から直接アクセスできないセキュアなサーバーの環境変数として管理し、クライアントから直接参照されない設計とすることが一般的に推奨されています。
7.2 バックエンド・プロキシによる一元管理とレート制限の適用
LLMのAPI呼び出しは、必ず自身が管理する「バックエンド・プロキシ(仲介サーバー)」を経由させてください。これにより、APIキーをサーバー内に完全に隠蔽し、安全な認証(OAuthなど)を通じて通信を保護できます。
さらに、プロキシ層で「1分間に何回まで」というレート制限(Rate Limiting)を設けることで、異常なリクエストの連打を防げます。万が一アプリが攻撃されても、被害額を最小限に抑える「防波堤」を自ら構築しましょう。
7.3 Identity-First(アイデンティティ主導)による一時的トークンの活用
最新のベストプラクティスは、静的なAPIキーを避け、動的に発行される「一時的トークン」を使用することです(Identity-Firstアーキテクチャ)。有効期限が極めて短いため、万が一漏洩しても被害が拡大しにくい特徴があります。
クラウドプロバイダーが提供する「ワークロード・アイデンティティ」などの機能を活用し、サーバー自体に権限を持たせることで、キーファイルそのものを管理しない「キーレスな運用」を目指しましょう。これが、現代のプロフェッショナルが取るべき究極の安全策です。
8. フリーランスを守る:LLM案件におけるコスト請求モデルと契約のベストプラクティス
技術的な対策と同じくらい重要なのが、クライアントとの「ビジネス上の契約」です。AI案件特有のリスクを契約書に明記しておくことで、不測の事態から自分自身の資産を守ることができます。
8.1 APIコストの請求モデル(パススルー型とインクルーシブ型)の設計
APIコストの支払いは、エンジニアが立て替えるのではなく、クライアント自身のクレジットカードで支払ってもらう「パススルー型(BYOK: Bring Your Own Key)」を基本としましょう。これにより、エンジニアはキャッシュフローのリスクを回避できます。
もし保守費用にコストを含める「インクルーシブ型」にする場合は、必ず「月間○万トークンまで」といった上限を設定してください。超過分は実費請求とするか、自動的にサービスを制限する旨を事前に合意しておくことが、トラブル防止の要です。
8.2 開発中のAPI実費請求と、支払い遅延に関する必須条項
開発やテスト段階でもAPIコストは発生します。これらは「開発実費」として、報酬とは別に請求できる旨を契約書に記載しておきましょう。「開発中に予想以上のコストがかかり、利益がなくなった」という事態を防ぐためです。
また、APIコストを立て替えている場合、クライアントからの支払遅延は資金繰りに影響を与える可能性があります。遅延損害金の規定を設けるなど、コストを回収するための法的手当てを検討しておくとよいでしょう。法的な不安がある場合は、弁護士などの専門家に相談し、条項の妥当性を確認することも一つの方法です。
8.3 修正回数(スコープ)の上限設定とデータ機密性の担保
LLMの回答は確率的で、「100%の正解」を定義しにくい側面があります。プロンプトの無限の微調整(スコープクリープ)を避けるため、無償での修正回数や期間を明確に定めましょう。
さらに、クライアントのデータを学習に利用させない「ゼロデータリテンション」の遵守も契約に盛り込むべきです。セキュリティ面での責任範囲を明確にすることで、万が一のデータ漏洩リスクに対して、自分自身が過度な法的責任を負わないように防衛してください。
9. まとめ:AI FinOpsスキルで市場価値を高め、次世代のフリーランスエンジニアへ
LLM APIのコスト最適化は、単なる「節約」ではありません。それは、AIの圧倒的な力を、企業のビジネスとして「持続可能な形」で提供するための高度なエンジニアリングです。
9.1 技術とビジネスの両輪でクライアントのROIを最大化する
2026年の優秀なエンジニアは、コードを書くだけでなく、クライアントの「投資対効果(ROI)」を最大化させる視点を持っています。AI FinOpsの実践は、技術的な専門性とビジネス的な判断力の両輪を証明する最高の手段となります。
コストを抑制しながら高品質なシステムを提案できるスキルがあれば、単なる実装担当にとどまらず、クライアントの事業戦略を支えるパートナーとして評価される可能性があります。
9.2 最新API動向とアーキテクチャの継続的なキャッチアップ
AIの世界は日進月歩であり、今日推奨される最適化手法が明日には古くなっていることも珍しくありません。各プロバイダーの利用規約や料金改定、新しいキャッシュ技術の登場などを常にキャッチアップし続ける姿勢が求められます。
常に一次情報にあたり、自身の設計をアップデートし続けることで、不測のリスクを回避し、常に最善のソリューションを提供できるよう努めてください。
9.3 統合的ソリューションを提供する「次世代AIエンジニア」としてのキャリア構築
コスト管理、セキュリティ、そして契約リテラシー。これらを統合して提供できる能力こそが、次世代のフリーランスエンジニアにとって重要な要素の一つといえるでしょう。。技術の力で世界を変えつつ、その基盤を現実的・財務的に支えるプロフェッショナルとして、あなたの市場価値はさらに高まっていくはずです。





